AIニュース
「同じ質問」なのに「違う答え」? 最新論文が暴く、マルチモーダルAIの“知覚の歪み”
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
「同じ質問」なのに「違う答え」? 最新論文が暴く、マルチモーダルAIの"知覚の歪み"
2025年12月9日、アムステルダム大学のAngela van Sprang氏やニュルンベルク工科大学のYuki M. Asano氏らの研究チームが論文「Same Content, Different Answers: Cross-Modal Inconsistency in MLLMs(同じ内容、異なる回答:MLLM(マルチモーダル大規模言語モデル)におけるクロスモーダルな不整合)」を発表しました。
私たちは普段、GPT-4oやClaudeといったマルチモーダルAIに対し、テキストでも画像でも「同じように理解してくれる」と期待して接しています。しかし、その信頼を揺るがすデータが突きつけられました。研究によると、現在の最先端AIは、情報の中身が全く同じであっても、それが「テキスト」で提示されるか「画像」で提示されるかによって、回答をコロコロと変えてしまうというのです。
「見て理解する」ことができるはずのAIが、実は見えているのに正しく考えられない。そんな認知的不協和のような状態に陥っていることを、本研究は「クロスモーダル・インコンシステンシー(異種間不整合)」と名付け、検証を行いました。今回は、15の最新モデルを対象に行われたこの大規模実験の詳細と、そこから見えてきたAIの意外な「癖」について、詳しく解説していきます。
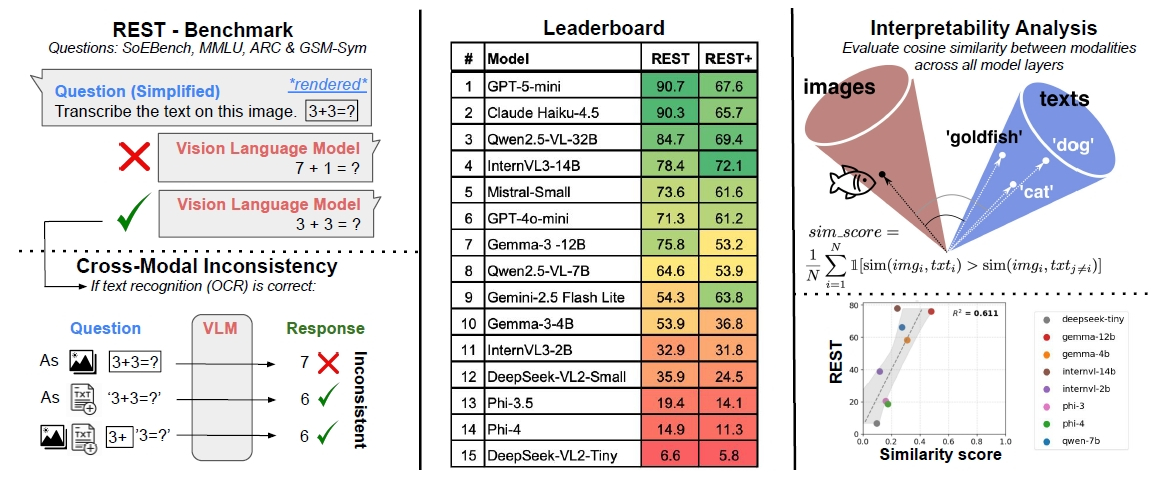
同じ内容でも形式次第で答えが変わってしまいます。画像は論文より。
「読めている」のに「解けない」? 脳と目が連携していないAIの実態
研究チームは、この問題を検証するために「REST(Render-Equivalence Stress Tests)」という新たなベンチマークを開発しました。仕組みは非常にシンプルかつ巧妙です。例えば「3+3=?」という質問を、「テキストのみ」、「画像のみ(文字が画像化されたもの)」、「混合(コンテキストは画像、質問はテキスト)」の3つの形式でAIに投げかけます。人間であれば、紙に書かれた計算式を見ても、口頭で聞かれても答えは「6」で変わりません。しかし、AIは違いました。
実験対象となったのは、GPT-5-mini、Claude Haiku 4.5、Qwen2.5-VLなど、2025年末時点でのフロンティアモデルたちです。驚くべきことに、これらすべてのモデルにおいて、入力形式が異なるだけで回答が食い違う現象が確認されたのです。
もちろん、研究チームは「OCR(文字認識)のミス」を排除して分析しています。つまり、AIは画像内の文字を「3+3」だと完璧に読み取れているにもかかわらず、計算や推論のフェーズに入ると、なぜかテキスト入力時とは異なる(しばしば間違った)答えを出してしまうのです。
このことは、AIにとって「文字として入力された情報」と「画像から読み取った情報」が、内部的に全く別物として処理されていることがわかります。人間で言えば、耳で聞いた話は理解できるのに、同じ内容を文字で読むと急に理解力が落ちるようなものでしょうか。特に、まだ学習データに含まれていない独自の方程式問題「SoEBench」を用いたテストでは、この傾向がより顕著に現れました。私たちが信じている「マルチモーダル」という言葉の裏には、実はまだ深い溝が横たわっているのです。

テキストより多くのトークンを消費するのに、画像の精度は低く非効率的です。
「テキスト至上主義」の限界と、画像処理の非効率な真実
興味深いのは、ほとんどのモデルが圧倒的に「テキスト入力」を好むという事実です。MMLUやGSM8kといった主要なベンチマークにおいて、画像形式で出題された際の正答率は、テキスト形式に比べて著しく低下しました。例えば、あるモデルではテキストなら解ける問題の約半数が、画像になった途端に解けなくなっています。
そこで思いつくのが「画像からテキストを抽出してから解かせる(OCR first)」という手法ですが、実際に試したところ、必ずしも改善にはつながらず、むしろパフォーマンスを悪化させるケースも見られました。
また、トークン効率の観点からも不都合な真実が明らかになりました。Qwen2.5-VL-32Bという例外を除き、多くのモデルは同じ情報を処理するために、テキストよりもはるかに多くの「視覚トークン」を消費しています。つまり、画像で情報を与えることは、AIにとって計算コストが高い上に、推論精度も下がるという「燃費の悪い」行為になってしまうのです。
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
ビジネスの現場では、資料のスクリーンショットをそのままAIに投げて要約させるといった使い方が普及しつつあります。しかし、この研究結果を見る限り、その方法はリスクを孕んでいます。重要な数字や論理が含まれる場合、面倒でもテキストとしてコピー&ペーストして渡した方が、AIの本来の知能を最大限に引き出せる可能性が高いと言えるでしょう。「画像も読める」機能はあくまで補助的なものであり、AIの「本能」は依然としてテキストにあるのです。
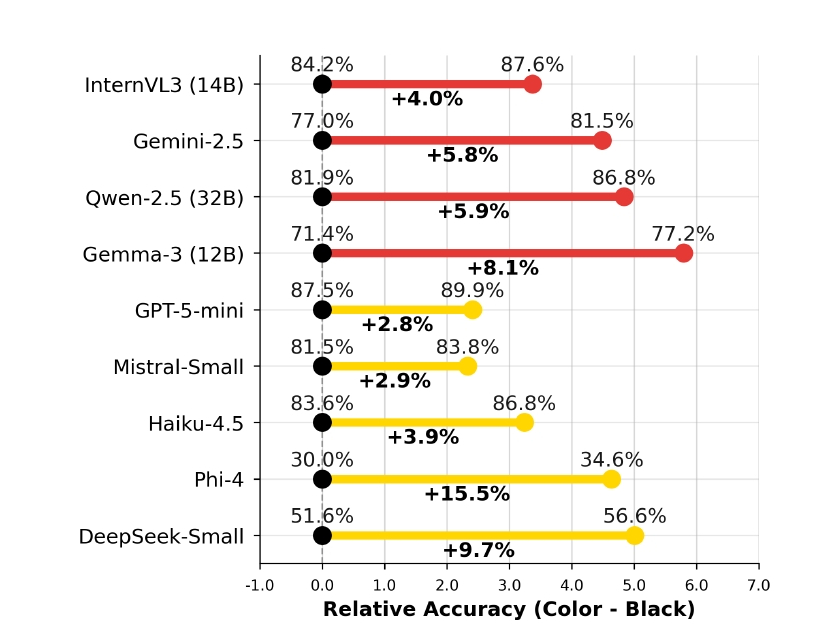
文字色を変えるだけで正答率が急上昇するのは不可思議です。
AIは「赤い文字」がお好き? フォントや色がもたらす謎のバイアス
研究チームはさらに踏み込んで、「REST+」という拡張ベンチマークを用い、画像の「見た目」が推論に与える影響も調査しました。フォントの種類(サンセリフ体、タイプライター体、筆記体)や解像度、そして文字色を変えてテストを行ったのです。その結果、意外な事実が判明しました。フォントの違いによる影響は軽微でしたが、解像度と「色」は無視できない影響力を持っていたのです。
解像度が低い(50 DPI)とOCR精度が落ち、結果として推論も失敗するのは直感的に理解できます。しかし不可解なのは、多くのモデルにおいて「黒い文字」よりも「赤い文字」や「黄色い文字」の方が、正答率が高くなる傾向が見られたことです。人間にとって、文字の色が赤だろうが黒だろうが「3+3」の答えは変わりません。しかしAIのニューラルネットワークの中では、特定の色が注意機構(アテンション)に何らかのポジティブな作用を及ぼしている可能性があります。
「重要なところは赤字にする」という人間界の常識が、AIの学習データを通じて、そのまま「赤字=重要=しっかり処理すべき」というバイアスとして定着しているのかもしれません。もしそうだとすれば、AIに画像を読み込ませる際、あえてテキストを派手な色に加工することで精度が上がるという、一種の「ハック」が成立することになります。これはAIの内部動作の不可解さを物語ると同時に、プロンプトエンジニアリングならぬ「画像エンジニアリング」の余地を示唆する興味深い発見です。
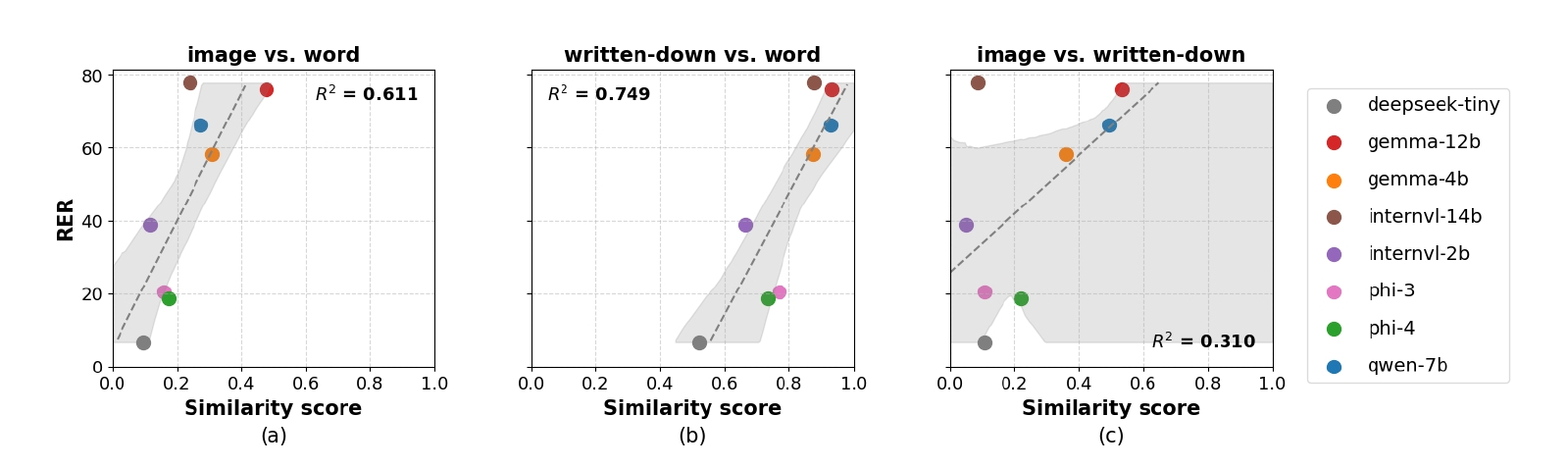
脳内の「距離」が原因。内部表現の類似度が高いほど一貫性も高まります。
「モダリティの断絶」を埋めるために
なぜ、このような不整合が起きるのでしょうか。研究チームは、モデル内部の「埋め込み表現(Embedding)」を分析することで、そのメカニズムに迫りました。その結果、テキスト入力時の内部表現と、画像入力時の内部表現が、ベクトル空間上で「近い」位置にあるモデルほど、一貫性が高い(=入力形式によらず同じ答えを出せる)ことが分かりました。逆に、不整合が多いモデルでは、同じ「金魚」という概念でも、テキストの「金魚」と画像の「金魚」が脳内の遠く離れた場所に保管されているような状態だったのです。
この「モダリティ・ギャップ」こそが、現在のマルチモーダルAIが抱える根本的な課題です。開発者たちは、テキストと画像を同じ空間に無理やりマッピングしようと努力していますが、完全な融合には至っていません。ユーザーである私たちは、AIが「マルチモーダル」を謳っていても、その内部では視覚と言語がまだ完全には手を取り合えていないことを理解しておく必要があります。
GPT-5-miniやClaude Haiku 4.5のような最新モデルでさえ、一貫性のスコアは90%程度にとどまり、約1割のケースでは入力形式によって答えが変わってしまいます。AIを業務フローに組み込む際は、可能な限り「テキスト」を正として扱い、画像認識結果は必ず人間がダブルチェックするか、あるいはテキスト化されたデータを別ルートで検証する仕組みが必要不可欠です。AIの目は進化していますが、その脳が目からの情報を正しく噛み砕けるようになるまでには、もう少し時間がかかりそうです。
この記事の監修

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
